One of the strangest facts about modern AI is that it is built on an objective that sounds almost absurdly simple.
Predict the next word. That’s it.
Not solve math problems.
Not understand language.
Not reason about the world.
Just predict what comes next.
At first glance, it feels far too simple to explain what systems like ChatGPT can do today. And yet, that single objective turns out to be far more powerful than it appears.
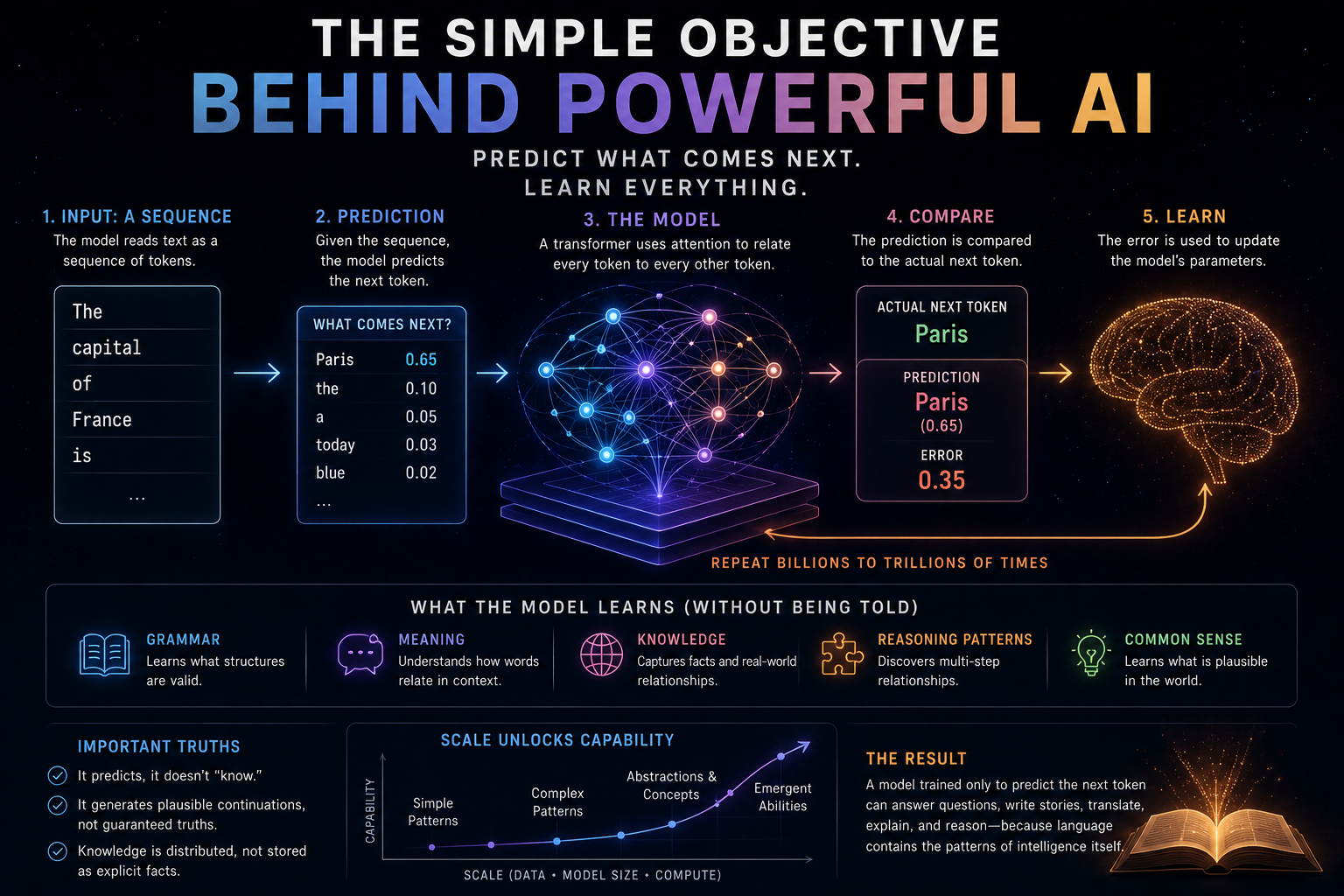
The Simple Task That Isn’t Simple
Imagine I give you the following sentence: The capital of France is…
Most people immediately think of Paris. But notice what just happened. You didn’t simply predict a word.
You used grammar.
You used meaning.
You used knowledge about the world.
You understood the relationship between France and its capital.
And then you selected the most likely continuation. A surprisingly large amount of intelligence was hiding inside a seemingly simple prediction. And that’s exactly the insight behind modern language models.
Prediction Forces Learning
I think many people assume AI systems are explicitly taught language rules.
Grammar rules.
Facts.
Reasoning strategies.
But that’s not really what happens. Instead, the model is given enormous amounts of text and asked a single question repeatedly: What comes next?
Every time it makes a prediction, reality provides an answer. The model compares its guess with the actual next word. Then it adjusts itself slightly. And the cycle repeats.
Again.
And again.
Billions of times.
Over time, something interesting begins to happen. The model discovers that certain patterns help it make better predictions.And because prediction is the only thing it cares about, it gradually becomes extremely good at finding those patterns.
Language Is Full Of Hidden Structure
The reason this works is that language isn’t random. Every sentence contains structure.
Grammar creates structure.
Meaning creates structure.
Context creates structure.
Knowledge creates structure.
Even reasoning creates structure.
If a model wants to become better at prediction, it must learn whatever structures help reduce error. Nobody explicitly teaches subject-verb agreement. The model discovers it because mistakes become costly. Nobody explicitly teaches relationships between concepts. The model discovers them because they improve prediction. Nobody explicitly teaches many forms of reasoning.
The model discovers useful reasoning patterns because they often help predict what comes next. The objective remains the same. But the knowledge required to succeed keeps expanding.
The Pressure To Compress Reality
The deeper I think about language models, the more they feel like compression systems. Not compression in the file-size sense. Compression in the intellectual sense. Imagine trying to predict billions of sentences without understanding anything. It would be impossible. The only way to improve consistently is to discover deeper regularities hidden inside the data.
Patterns about language.
Patterns about people.
Patterns about how the world works.
The model is constantly searching for simpler explanations that account for more observations. And those explanations become embedded inside its parameters. In a strange way, prediction pressures the system to build increasingly useful internal models of reality. Not because it wants understanding. Because understanding is useful for prediction.
Why Scale Matters So Much
This also explains one of the most surprising discoveries in modern AI. Scale changes everything. With small amounts of data, a model learns simple patterns.
With more data, it learns richer ones.
With larger models, it can represent increasingly complex relationships.
With more computation, those relationships become more refined.
At some point, the system begins capturing abstractions that were previously invisible.
Patterns become concepts.
Concepts become relationships.
Relationships become behaviors that start looking remarkably intelligent.
Nothing about the objective changed. Only the scale did.
The Important Limitation
But there is an important distinction here. The model is not trying to be correct. It is trying to be predictive. Those are not always the same thing. A response can sound plausible while being completely wrong. A statement can fit the surrounding context while failing to match reality. Because the model is optimized to continue patterns in language. Not to verify truth.
That distinction explains many of the strengths and weaknesses of modern AI systems. They are often extraordinarily fluent. Sometimes astonishingly knowledgeable. And occasionally very confidently incorrect.
The Bigger Lesson
What fascinates me most about large language models is that intelligence wasn’t engineered directly. Researchers did not sit down and write code for reasoning. Or understanding. Or explanation. Instead, they created a system that became increasingly good at prediction. And as prediction improved, many of the capabilities we associate with intelligence began emerging naturally. Which suggests something deeper.
Maybe language contains far more structure than we once realized. Or maybe intelligence itself is more connected to prediction than we thought. Either way, the result is remarkable. A machine trained to guess the next word eventually learns enough about language, knowledge, and the world that it starts looking surprisingly intelligent.
And it all begins with a question that sounds almost trivial: What comes next?