One of the most important things to understand about machine learning is that not all learning works the same way. People often talk about “AI learning” as if there is one universal mechanism underneath everything. But once you look closer, a more fundamental question appears:
What kind of feedback does the system actually receive while learning? Because that changes the problem entirely.
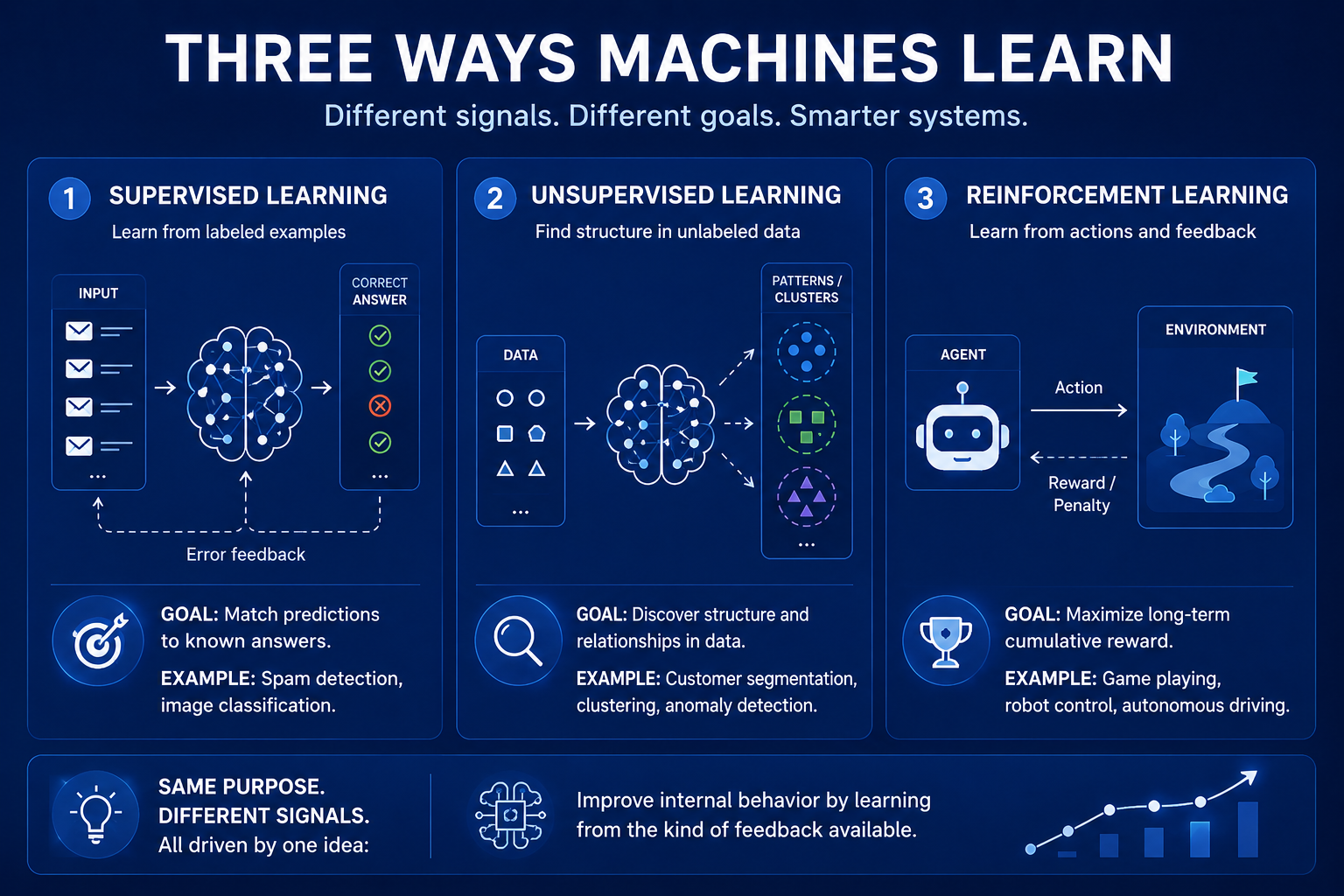
In some cases, the system is told the correct answer directly.
In others, it receives only raw data with no guidance at all.
And sometimes, it learns only through the consequences of its own actions over time.
Those are not small implementation differences. They represent fundamentally different ways of extracting intelligence from experience.
The Simplest Case: Learning From Correct Answers
Imagine training a system to recognize spam emails.
You give it examples:
- this email is spam
- this one is not
- this one is spam again
The system makes predictions, compares them against the known answers, and gradually adjusts itself to reduce mistakes.
This is supervised learning. And conceptually, it is probably the easiest type of machine learning to understand. The system learns through direct correction.
Every prediction comes with immediate feedback: right or wrong
That creates an extremely strong learning signal. Over time, the model begins discovering patterns that connect inputs to outputs:
- suspicious phrases
- unusual formatting
- link structures
- sender behavior
The goal is simple: align predictions as closely as possible with the provided labels. And this approach turns out to be incredibly powerful. A huge percentage of modern AI systems rely heavily on supervised learning because labeled data provides a stable and efficient way to shape behavior.
But it also comes with a limitation. Someone has to provide the answers. And in the real world, labeled data is often expensive, incomplete, or impossible to scale cleanly. Which leads to a very different kind of learning.
Learning Without Answers
Now imagine giving a system massive amounts of data without any labels at all.
No “correct” outputs.
No explicit guidance.
No examples of what the right answer looks like.
At first, that almost sounds impossible. How can a system learn if nobody tells it what is correct?
But the answer is surprisingly interesting:
it can still learn structure.
This is unsupervised learning. Instead of matching predictions to labels, the system tries to uncover hidden regularities inside the data itself.
It might:
- group similar items together
- detect anomalies
- compress information
- discover recurring patterns
- identify hidden relationships
For example, if you feed a model thousands of unlabeled images, it may naturally begin clustering visually similar objects together. Not because it “understands” cats or cars. But because the statistical structure of the data contains patterns worth organizing. And I think this reveals something deeper about intelligence itself.
Sometimes learning is not about being told the answer.
Sometimes it is about discovering structure independently.
That idea becomes increasingly important in modern AI because the internet contains enormous amounts of unlabeled information. Far more than humans could ever manually annotate.
The Most Interesting Case: Learning Through Consequences
Then there is reinforcement learning.
This is where things start becoming much closer to real-world decision-making.
Instead of receiving direct answers, the system interacts with an environment:
- it takes actions
- receives outcomes
- and gradually learns which behaviors lead to better long-term results
The key difference is that feedback becomes delayed and indirect. Imagine teaching a system to play chess.
You do not necessarily tell it:
“this exact move was correct”
Instead, it plays games and eventually discovers whether it won or lost.
Now the system faces a much harder problem:
which earlier decisions actually contributed to the outcome?
That uncertainty changes the nature of learning completely. Because now intelligence is not just pattern recognition. It becomes strategy.
The system must balance:
- exploration
- experimentation
- optimization
- risk
- long-term consequences
And that starts resembling many real-world problems humans face constantly.
Driving.
Negotiation.
Resource allocation.
Scientific experimentation.
Business strategy.
In real life, feedback is rarely immediate or perfectly labeled. We often learn through consequences. And reinforcement learning attempts to capture that structure computationally.
Why These Differences Matter
At first glance, these three approaches may seem like technical categories. But they actually reflect something much deeper. They represent different relationships between:
- information
- feedback
- uncertainty
- and adaptation
In supervised learning:
the world provides answers.
In unsupervised learning:
the world provides structure.
In reinforcement learning:
the world provides consequences.
And each creates different strengths and weaknesses. Supervised learning tends to be efficient but depends heavily on labeled data. Unsupervised learning scales more naturally but often lacks clear objectives. Reinforcement learning enables strategic behavior but introduces massive complexity because outcomes unfold over time.
Modern AI increasingly combines all three. And that combination is part of why current systems feel dramatically more capable than earlier generations of software.
The Bigger Shift
I think one of the most interesting implications of machine learning is that intelligence starts looking less like a fixed property and more like a process of adaptation under feedback.
Different systems learn differently because different environments expose different kinds of signals.
Some environments provide explicit answers.
Some only expose hidden structure.
Some force systems to discover meaning through consequences over time.
But underneath all of them, the core idea remains surprisingly consistent:
Learning is ultimately about changing internal behavior in response to experience.
And once machines became capable of doing that at scale, software stopped being static.
It became adaptive.
Which may have been the real beginning of modern AI.