One of the easiest ways to misunderstand machine learning is to imagine that models somehow “understand” raw data directly.
But they don’t.
A machine learning system never sees the world the way humans do. It does not look at a house and intuitively understand neighborhood quality, architecture, or emotional value. It does not read an email and experience suspicion.
What it sees are signals.
Numbers.
Patterns.
Relationships.
And that raises an important question: If a system is improving over time, what exactly inside it is changing? Because something clearly changes.
The data itself does not change.
The task usually stays the same.
The outside world remains what it is.
So the only place learning can happen is inside the system’s internal structure.
What the System Pays Attention To
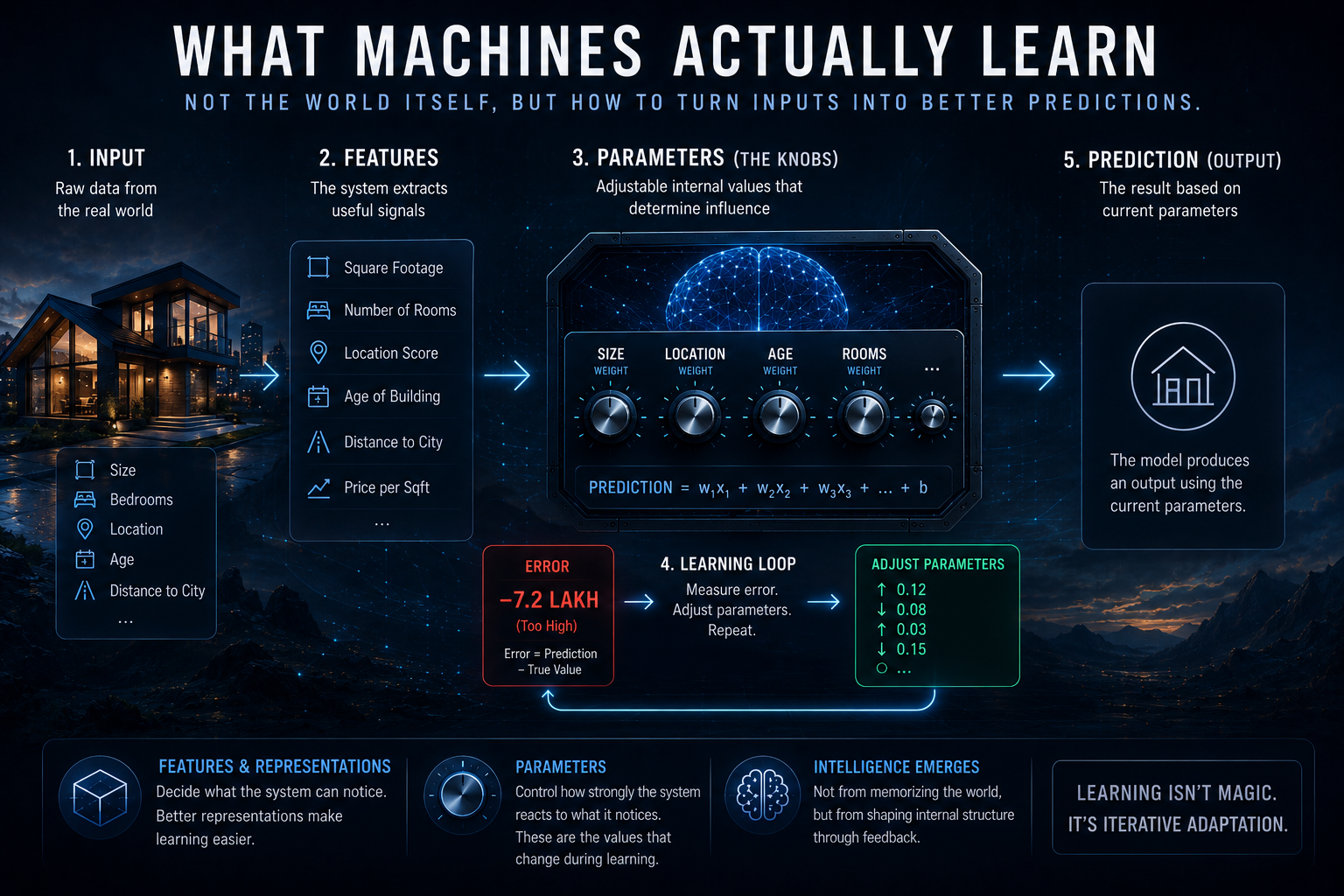
Take a simple example: predicting house prices. A model might receive inputs like:
- square footage
- number of bedrooms
- location
- age of the building
At first glance, those just look like pieces of information. But the model still has to decide what parts of that information actually matter. That is where features come in. A feature is simply something the system uses as a signal while making predictions. In spam detection, features could include:
- suspicious words
- unusual links
- sender patterns
- message structure
In house pricing, location may become far more important than the color of the walls. And this matters because the real world is messy. Raw data contains enormous amounts of irrelevant information. Features are essentially the system’s attempt to separate signal from noise. A model can only learn from patterns it is capable of noticing. Which means bad features create bad learning.
If you completely ignore location while predicting house prices, even a powerful model will struggle. Not because it lacks intelligence, but because one of the most important signals never enters the system meaningfully.
The Hidden Knobs Inside Learning
But recognizing signals is only part of the process. The model still has to decide:
- how strongly each feature matters
- which patterns deserve more influence
- how different signals combine together
This is where parameters enter the picture. Parameters are the adjustable internal values that shape the model’s behavior. You can think of them as knobs.
One knob controls how much square footage affects price.
Another adjusts the importance of location.
Another changes how strongly age impacts value.
Learning happens by adjusting those knobs repeatedly. If the model consistently undervalues larger houses, it increases the influence of size-related parameters. If it overestimates prices in certain neighborhoods, those parameters shift downward. Over time, the system reshapes itself around patterns in the data. And this is the strange part about machine learning: What looks like intelligence externally is often just the accumulation of millions or billions of tiny parameter adjustments internally.
The More Important Layer Nobody Talks About
But modern AI goes even deeper than that. Because advanced systems do not just rely on human-defined features anymore. They learn internal representations automatically. This is one of the biggest reasons modern AI feels dramatically more powerful than older software systems.
Take image recognition. At the beginning, the system only receives pixels. Tiny numerical values arranged in grids. But as information moves through the model, something interesting happens.
Early layers begin detecting edges.
Later layers detect shapes.
Then textures.
Then objects.
Then faces.
The model gradually constructs increasingly useful internal representations of the world. And nobody explicitly programs those representations manually. They emerge because they become useful for reducing error. That turns out to matter enormously. Because intelligence is not just about learning faster. It is also about representing reality in the right way. A better representation can make an impossible problem suddenly become solvable. And I think this is one of the most underrated ideas in AI.
How a system sees the world often matters more than how fast it learns.
Why More Data Is Not Always Better
One misconception people often have is that machine learning improves automatically with more information. But more features do not necessarily create better intelligence. Sometimes they create confusion. If you add hundreds of meaningless signals:
- random numbers
- irrelevant variables
- noisy correlations
The model may begin learning accidental patterns that do not actually matter. And because machine learning systems optimize statistically rather than conceptually, they can become surprisingly good at learning the wrong things. A model does not “know” that larger houses are valuable in the human sense. It only adjusts numbers until predictions align with patterns inside the data.
That distinction matters more than most people realize. Because models optimize for correlation, not meaning.
The Real Nature of Learning
At its core, machine learning is not about machines suddenly becoming conscious or self-aware. It is about systems gradually reshaping internal structure through feedback.
- Inputs enter.
- Signals are extracted.
- Internal parameters combine those signals into predictions.
- Errors create feedback.
- Parameters adjust.
The cycle repeats. Again and again.
And eventually, behavior changes because the structure inside the system changes. The deeper you look, the more modern AI starts feeling less like magic and more like an enormous process of iterative adaptation. Not unlike evolution itself.
Small adjustments.
Repeated endlessly.
Until surprisingly intelligent behavior begins to emerge from the accumulation.